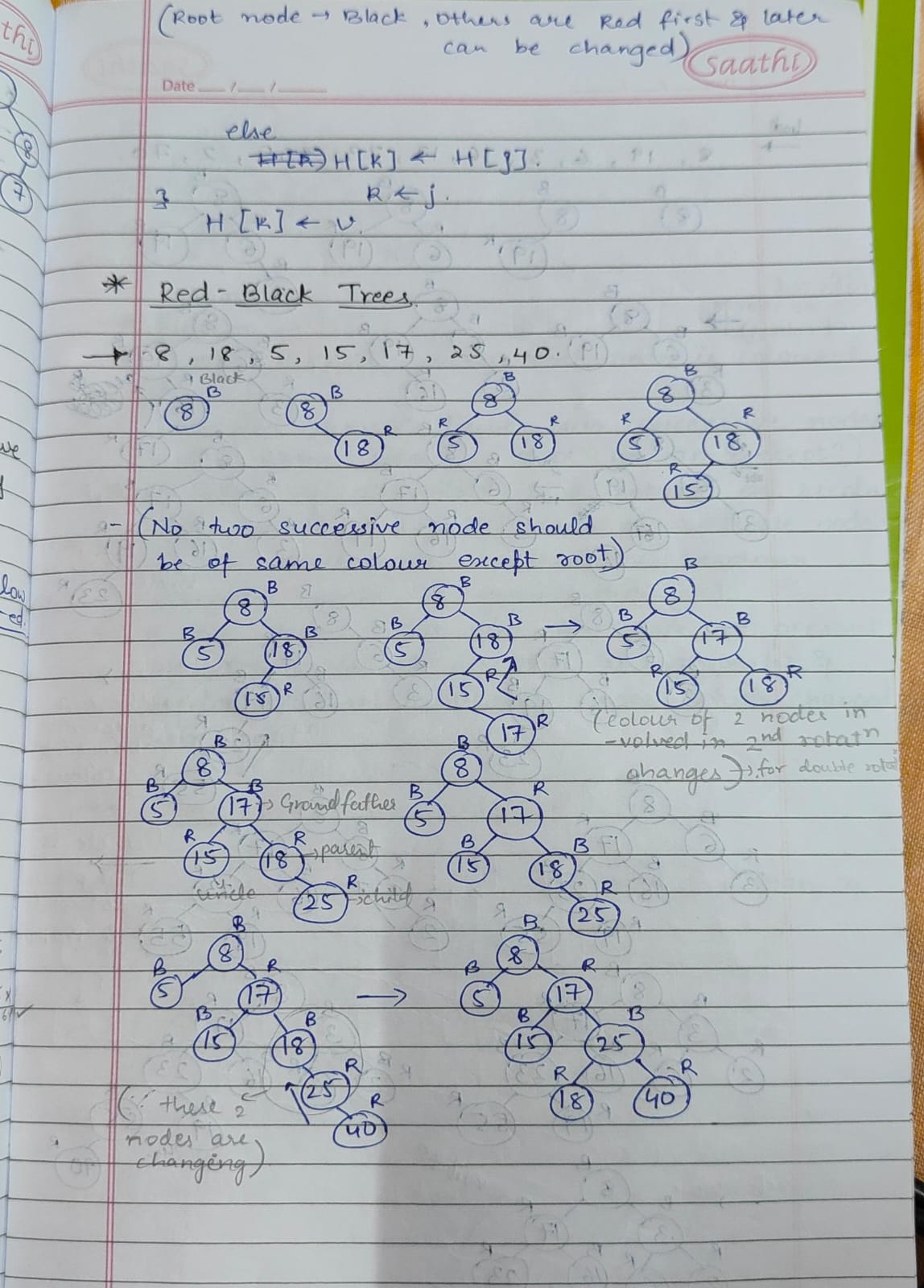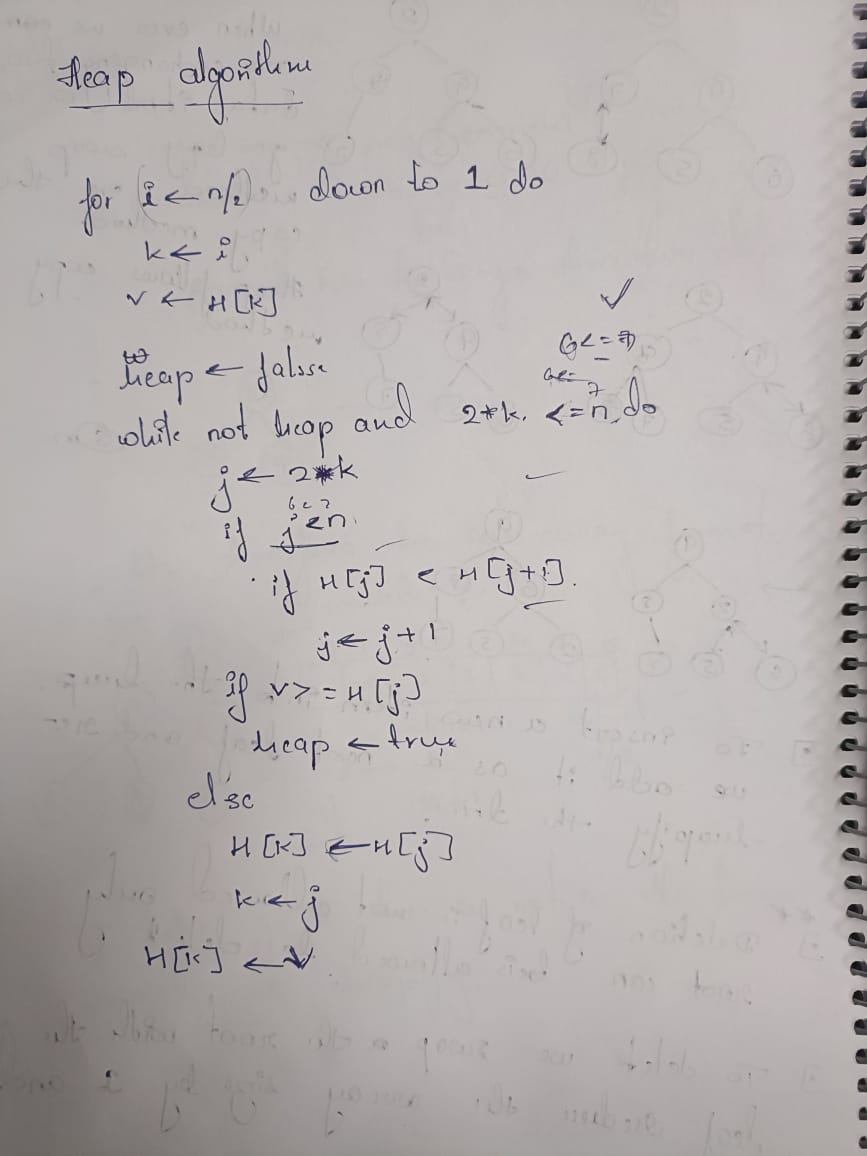course learnings
LEARNINGS FROM THE COURSE
-> Hierarchical data structures like trees organize information in parent-child relationships. BST enables fast searches, but balancing is crucial, addressed by AVL or Red-Black trees. Heaps manage priority tasks efficiently, while Tries excel in prefix searches like auto-complete. Each tree optimizes specific operations, making them vital for various applications.
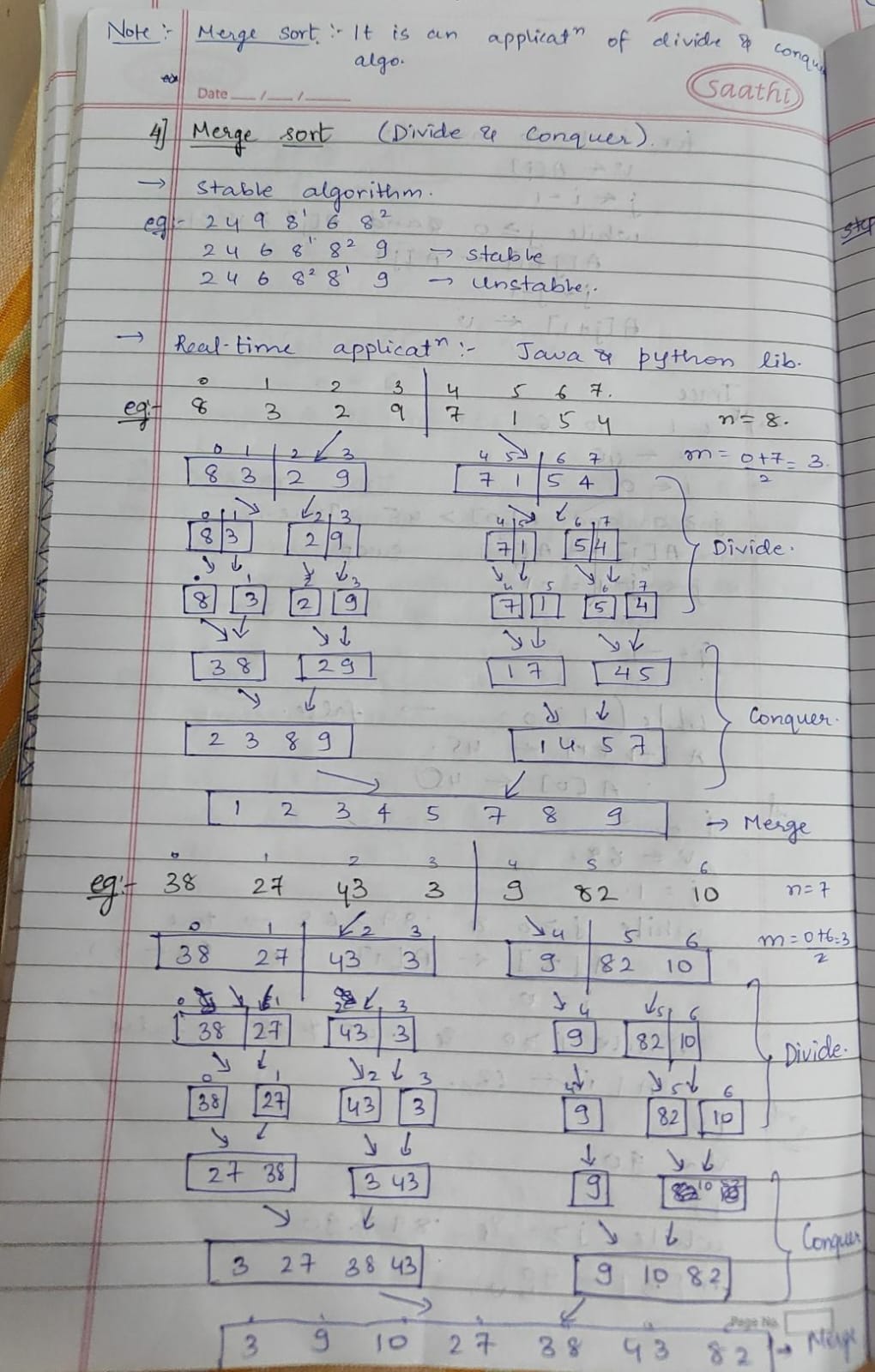
-> Array query algorithms solve problems like range sums or maximum values efficiently. Segment Trees and Fenwick Trees allow logarithmic time operations, handling even large datasets. These algorithms are crucial in data analytics, competitive programming, and real-time systems requiring quick computations.
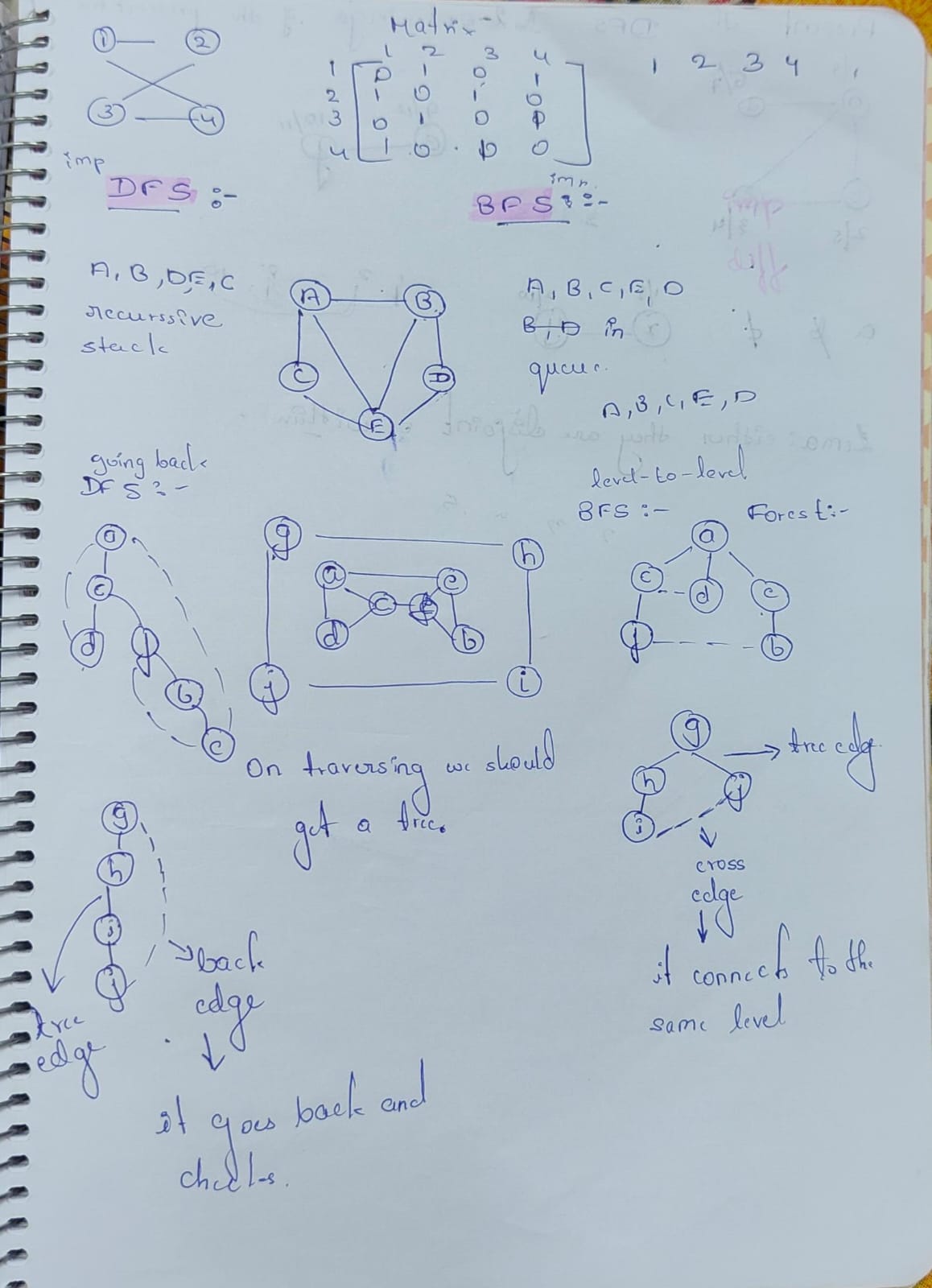
-> Trees are hierarchical and cycle-free, used in structured data like file systems. Graphs are flexible with complex connections, ideal for networks and paths. Tree traversals (Inorder, Preorder) suit hierarchy processing, while graph traversals (BFS, DFS) explore connectivity and shortest paths.
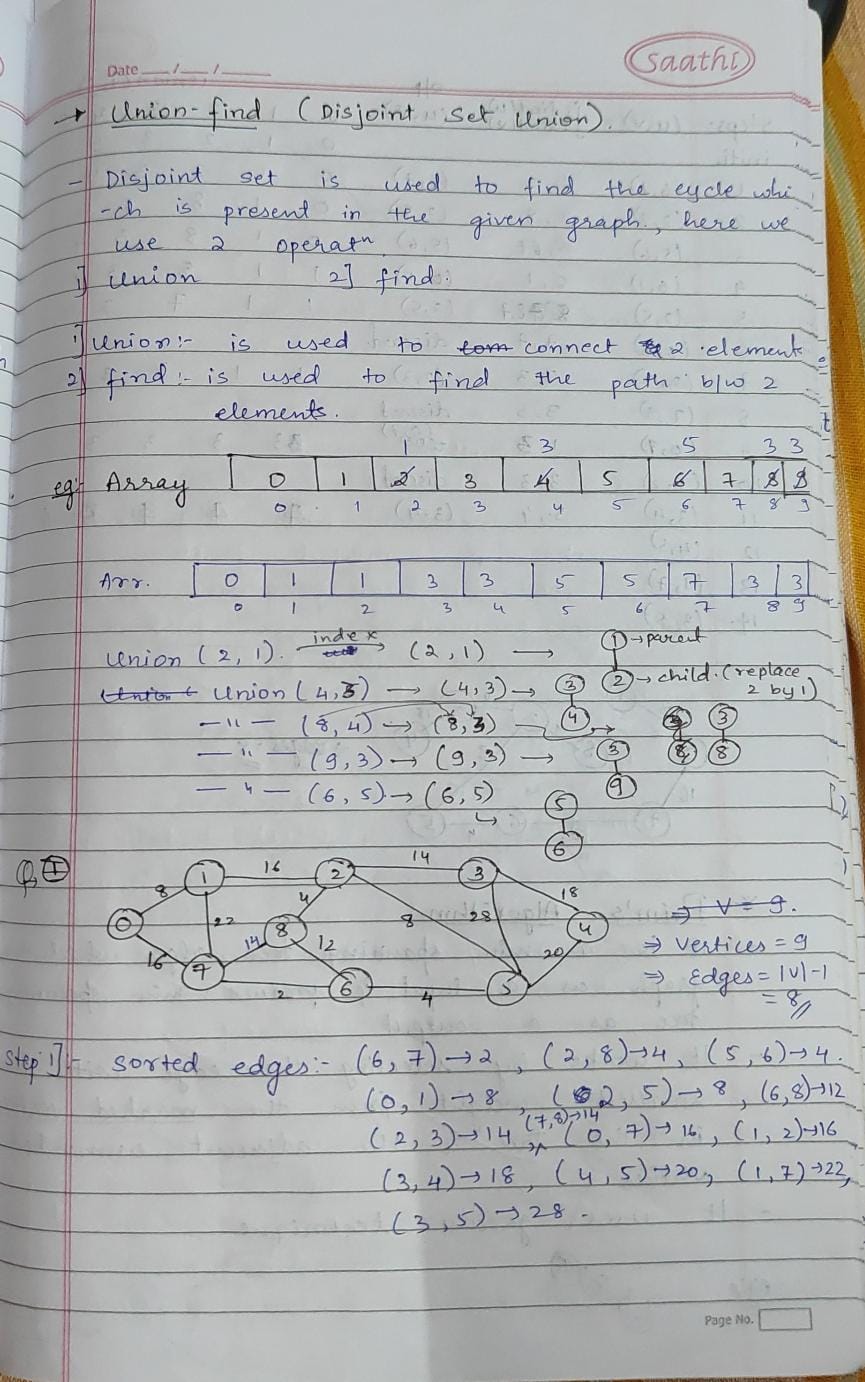
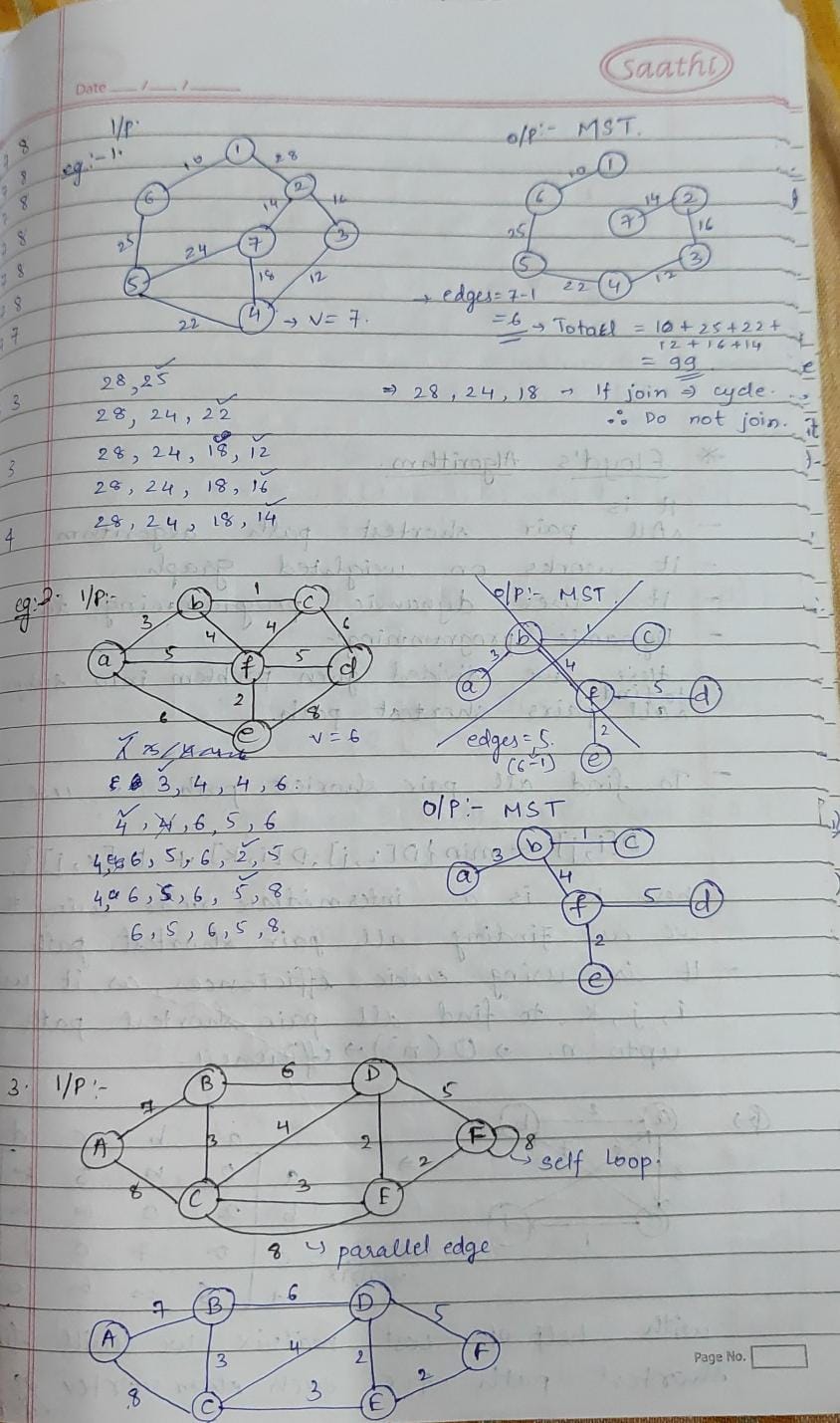
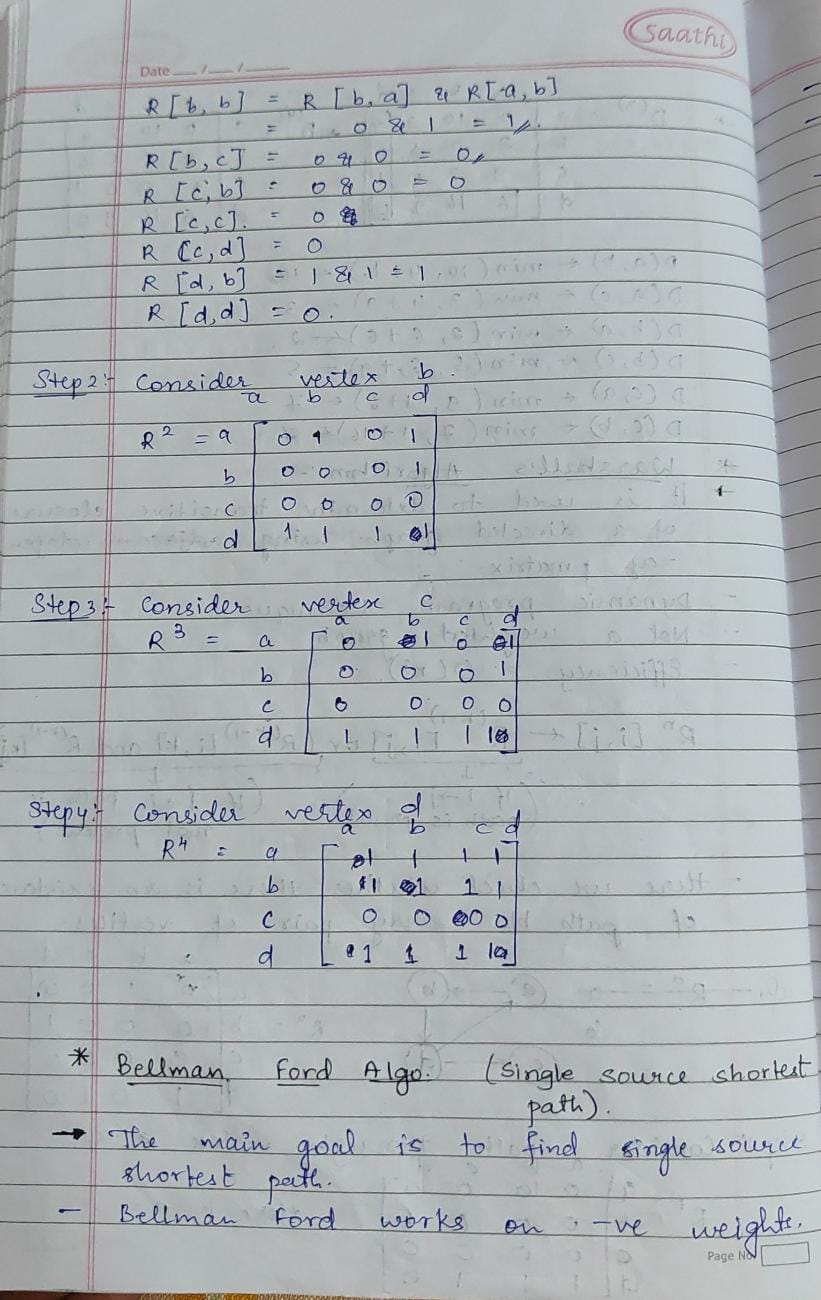
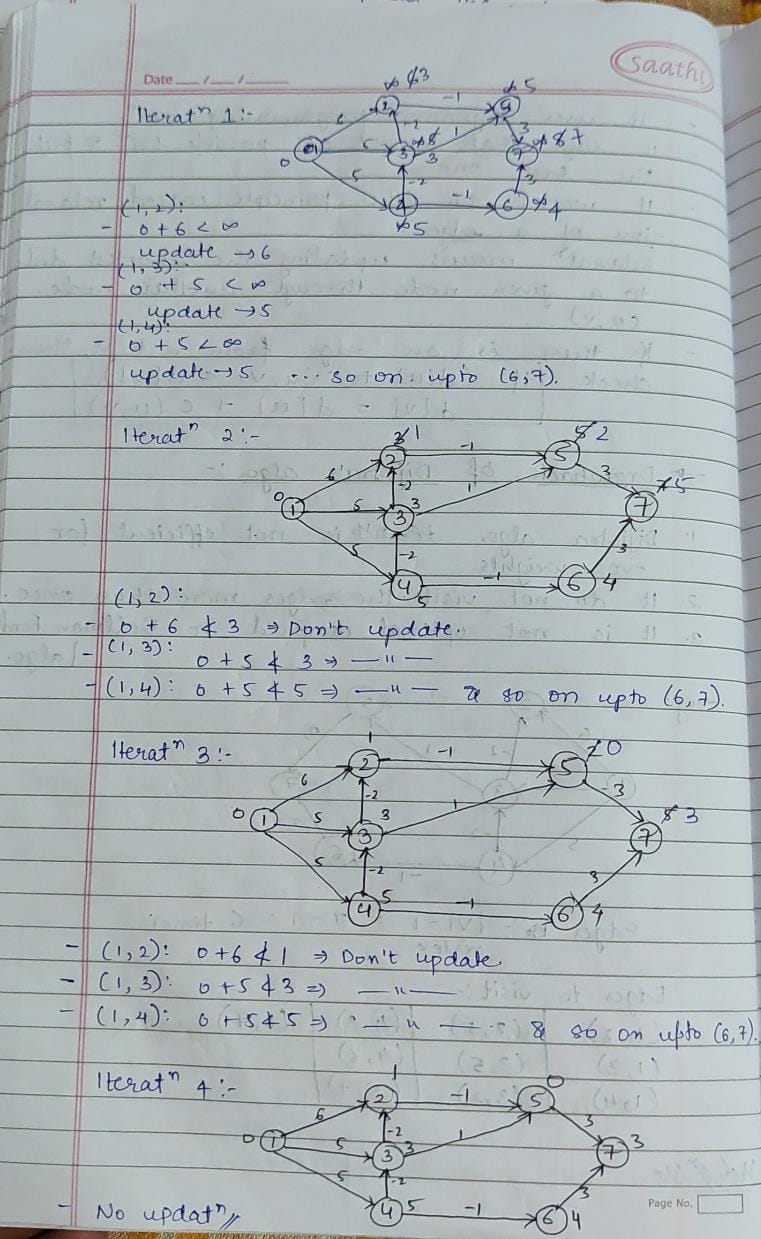
-> Spanning tree algorithms like Kruskal’s minimize costs in network design. Shortest path algorithms like Dijkstra’s are essential for navigation apps and logistics. These algorithms optimize connectivity and route planning in real-world networks, enhancing efficiency.